
In large-scale data ingestion systems, small architecture choices can have dramatic performance implications.
During my time at AWS CloudWatch, we were in the midst of a migration from our legacy metric stack to a spanky new one. I was the on call engineer as our alarms blared: end-to-end latency spikes had breached a critical threshold. A quick partitioning tweak later, those noise-making spikes vanished and throughput climbed 30% on the same hardware. In this deep-dive, you’ll see exactly how I diagnosed a flawed “uniform message” assumption and turned it into high-volume reliability.
The System Architecture
The data pipeline processed messages from a number of queues, each of which had its own priority setting.
The architecture looked like below:
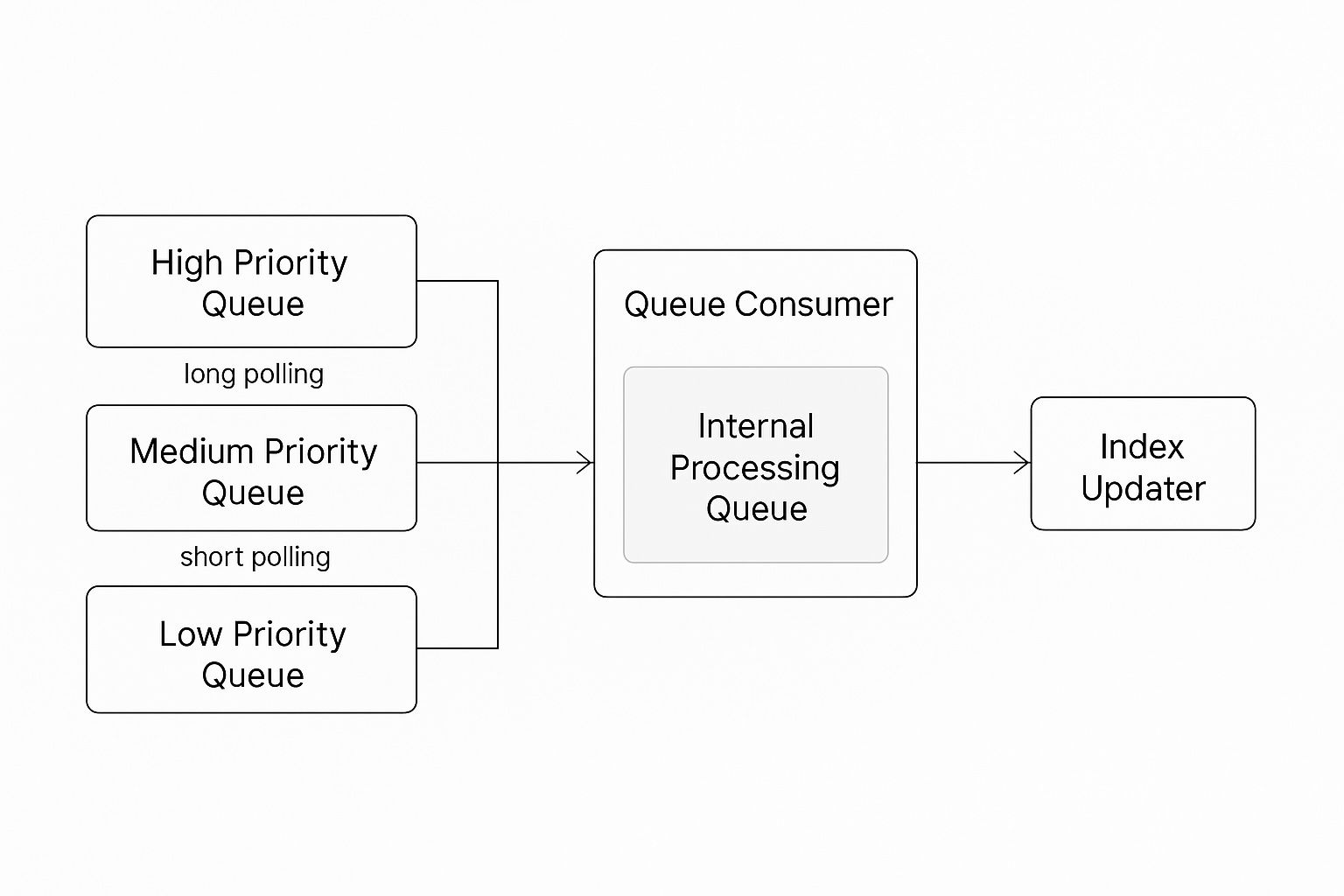
The distributed queue consumer worked with a simple algorithm.
- Poll through queues in listed priority order and read available messages.
- Add messages to an internal processing queue till the buffer reaches maximum capacity.
- Flush the buffer.
Long polling was employed for higher priority queues to ensure more messages were picked up to minimize end-end latency, whereas the lower priority queues were polled for a shorter period of time in order to prevent priority inversion. This was crucial for maintaining SLA of the broader data pipeline.
Message Processing Flow
Messages in this system usually fit into two categories of operations:
- Adding new items to an index
- Deleting items from an index.
These messages would be read by the queue consumer, processed, and then sent to downstream systems for indexing with the results. Simple and clear-cut—or so it appeared.
Problem: Message Size Variance
Everything functioned as anticipated during early production deployment and initial testing. As scale grew, though, we started to see occasional end-to-end latency spikes, especially at the top of every hour when some message types would flood. Extensive research revealed a basic assumption ingrained in our design: we had assumed messages across several queues would be approximately same in size. Actually, delete messages were far bigger than add ones.
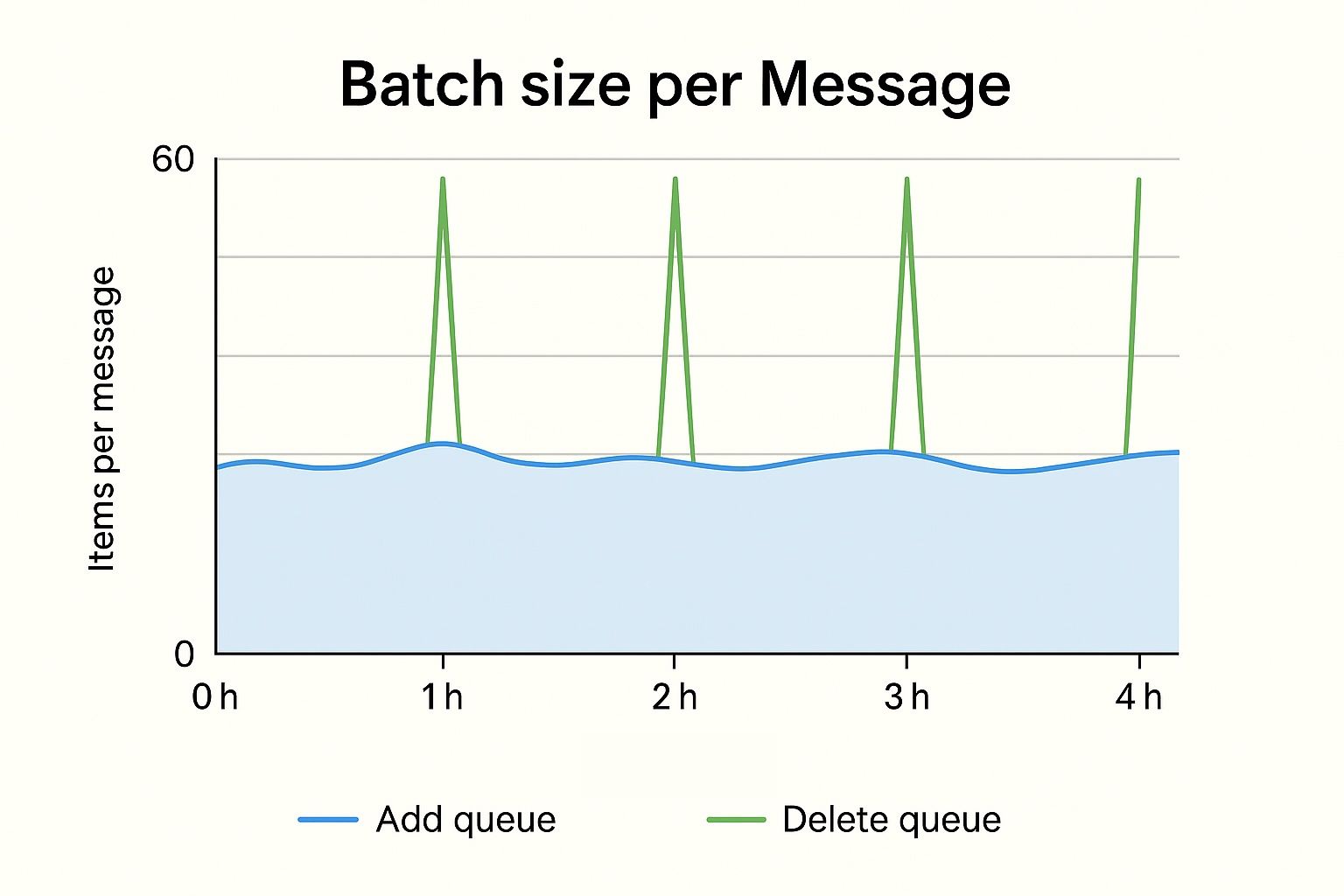
This size difference set off a chain reaction:
- Processing larger messages (deletes) took more time.
- Many large delete messages arriving simultaneously would mean that the buffer filled with more deletes instantly before cycling back to a higher priority queue.
- This resulted in periodic latency spikes in "lumpy" processing patterns.
Most troubling was that these processing imbalances were really countering our priority queue consumer design. During peak times, large, low-priority messages were practically crowding out smaller, higher-priority ones.
Root Cause: Mental Model Mismatch
The queue consumer filled its buffer under the assumption that all messages had a uniform distribution in the operations. In reality, the number of operations contained within each message varied dramatically - some delete messages contained 50+ operations, while add messages typically contained 1-5 operations.
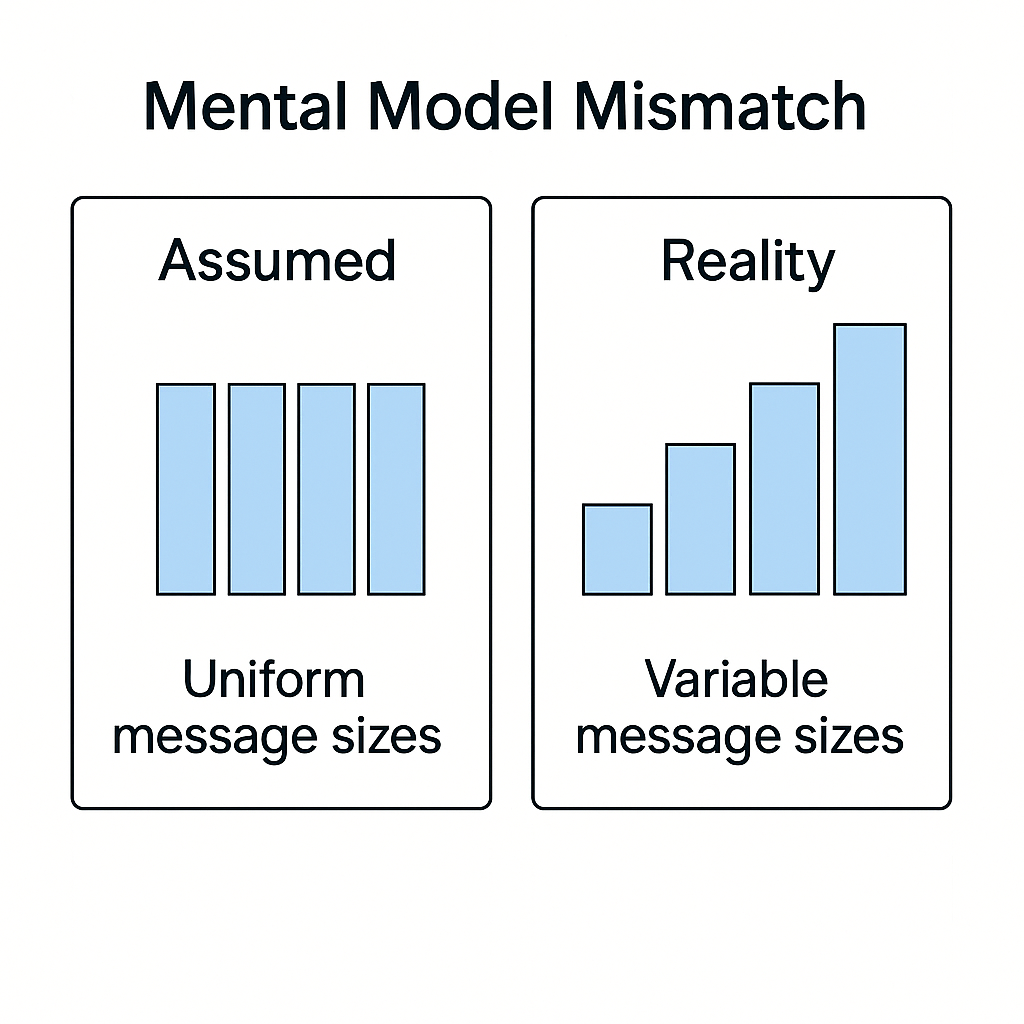
This mismatch between our mental model (messages as atomic units of work) and reality (messages as variable-sized containers of work) was the manifestation of the performance bottleneck.
Solution: Message Partitioning and Normalization
The analysis of message size distributions indicated that normalization is necessary to ensure uniform processing features regardless of the message arrival rate.
The next steps were clear:
- Split oversized messages into smaller, consistently sized chunks while maintaining message integrity.
Tuning: Finding the Optimal Threshold
However, the core challenge was selecting a threshold such that below conditions were satisfied.
- Minimizes splits for large add operations (which are rare)
- Maximizes splits for delete operations (which are large and batched at the top of the hour)
Enter, statistical analysis!
Let:
- \( A \): Add message size distribution
- \( D \): Delete message size distribution
- \( P_{95}(A) \): 95th percentile of adds (95% ≤ this value)
- \( P_{5}(D) \): 5th percentile of deletes (95% ≥ this value)
Optimal Threshold:
\[ T = \max\left(P_{95}(A),\ P_{5}(D)\right) \]
Note, this partitioning needs to be implemented upstream. This way the core algorithm for the priority queue consumer does not need to be changed and we maintain separation of concerns overall.
Results: Dramatic Performance Improvement
The impact of this seemingly simple change was profound.
After implementing message partitioning:
- Processing became more consistent across all message types.
- The hourly latency spikes disappeared entirely.
- System throughput improved by approximately 30%.
Most importantly, batches sent to downstream systems now contained a more balanced mix of operations, even during peak periods. The system maintained its priority guarantees while eliminating the processing bottlenecks caused by message size variance.
Anecdotally, delete messages were now split into 3+ smaller messages, while add messages were rarely split. This normalization of message sizes ensured that the queue consumer was working with much more uniform units of work.
Broader Applications for Large-Scale Ingestion Systems
While this specific solution addressed a particular issue in a search indexing system, the principles apply broadly to large-scale ingestion systems:
- Question assumptions about uniformity: Many system designs assume uniform processing characteristics that don't hold at scale. Identifying and challenging these assumptions is crucial.
- Look for normalization opportunities: Normalizing work units (whether message size, processing time, or resource consumption) can dramatically improve predictability and throughput.
- Use data to guide partitioning: The specific thresholds for our partitioning logic came from actual production data. This data-driven approach ensured we were optimizing for real-world conditions, not theoretical scenarios.
- Solve problems at the right layer: By implementing partitioning upstream from the queue consumer, we avoided complicating the core processing logic.
- Think in terms of work units: Rather than treating messages as atomic units, conceptualize in terms of discrete work units. This mental model opens up opportunities for optimization.
Monitoring and Metrics
To even have data to come up with above hypothesis, I recommend tracking these key metrics:
- Message size distribution: Understand the variance in your message sizes across different message types.
- Processing time per message: Identify correlations between message size and processing time.
- Queue depth over time: Detect patterns in how queues build up and drain.
- End-to-end latency: The ultimate indicator of system health.
With these metrics in place, you can identify size-related bottlenecks and determine appropriate thresholds for message partitioning.
Conclusion
Building high-performance, large-scale ingestion systems requires moving beyond textbook approaches and adapting to real-world complexities. The message partitioning solution I've described exemplifies how seemingly small optimizations can have outsized impacts on system performance.
What makes this approach particularly powerful is its simplicity and broad applicability. You don't need complex algorithms or expensive resources to implement message partitioning-just a clear understanding of your workload characteristics and a willingness to challenge assumptions.
If you're facing similar challenges with uneven processing in your high-volume queue systems, I encourage you to consider whether message partitioning might be the right solution for you.