
Introduction
- Reliability and Scalability of a system is dependent on how application state is managed.
- Initially started with just a focus on applications which require just "Primary Key" access.
- Data is partitioned and replicated using consistent hashing.
- Replica consistency maintained by a quorom like technique and decentralized replica synchronization protocol.
Why Dynamo?
- Most production systems store their state in relational databases. For many of the more common usage patterns of state persistence, however, a relational database is a solution that is far from ideal. Most of these services only store and retrieve data by primary key and do not require the complex querying and management functionality offered by an RDBMS.
Dynamo Assumptions
- Simple key value store with no relational schema.
- Store relatively small objects.
- Lower consistency requirements.
Design Considerations / Tenets
- Always write-able.
- Latency Sensitive.
- Conflict resolutions for multiple copies of data only happens during a read. Either the data-store or the application can manage these conflict resolutions. Application can choose to "merge" different versions whereas the data-store can use a simpler scheme such as last write wins.
- Incremental stability: Addition of new storage nodes should be pain free.
- Symmetry: All nodes share the same responsibilities.
- Decentralization
- Heterogeneity
Opinion: Symmetry and Heterogeneity as tenets do not seem to go well together and contradict each other. More on this later.
Discussion
- Dynamo can be characterized as a zero-hop DHT, where each node maintains enough routing information locally to route a request to the appropriate node directly.
Dynamo API Interface
- get(key) : Locates the object replicas associated with the key in the storage system and returns a single object or a list of objects with conflicting versions along with a context.
- put(key, context, object) : Determines where the replicas of the object should be placed based on the associated key, and writes the replicas to disk. The context encodes system metadata about the object that is opaque to the caller and includes information such as the version of the object. The context information is stored along with the object so that the system can verify the validity of the context object supplied in the put request.
Opinion: If context is opaque to the caller, how is version information computed, does every write operation necessitate a read? Edit: Further in the paper, the authors do clarify that that is the case.
Partitioning Algorithm
A variant of the consistent hashing algorithm is used. In the "normal" consistent hashing algorithm each storage node is only responsible for one point (portion) of the ring.
- Each storage node gets assigned to multiple points in the ring. To address this, "virtual nodes" are used. A virtual node looks like a single node in the system, but each node can be responsible for more than one virtual node.
Replication
- Each item is replicated to "N" hosts which is configured per Dynamo instance.
Note: The paper makes a reference to a "Co-ordinator" node without being clear on the nomenclature. Consistent hashing makes use of a ring as the output range of underlying hash function. Nodes are assigned positions on the ring. On hashing of an item, it reveals that the position on the ring. A node is responsible for the region of the ring between itself and its predecessor. Therefore the item would need to land on the first position which is larger than the hashed items' position. The node where an item lands on is called a "Co-ordinator" Node.
- Co-ordinator node also replicates the key that it needs to be in charge of, to "N-1" clockwise successor nodes.
- Each key has list of nodes that are responsible for it. This list of nodes is called
"preference list". Because of the presence of virtual nodes (co-located on the same host), the preference list usually only contains distinct physical nodes.
Data Versioning
Dynamo uses Vector clocks in order to capture causality between different versions of the same object.
- Each object version has its own vector clock. Each vector lock is list of (node, counter) pairs. If first and second versions of objects have vector clocks such that counters present on the first object are higher than the counters present on the second object, it means the versions are in conflict are not ancestors!
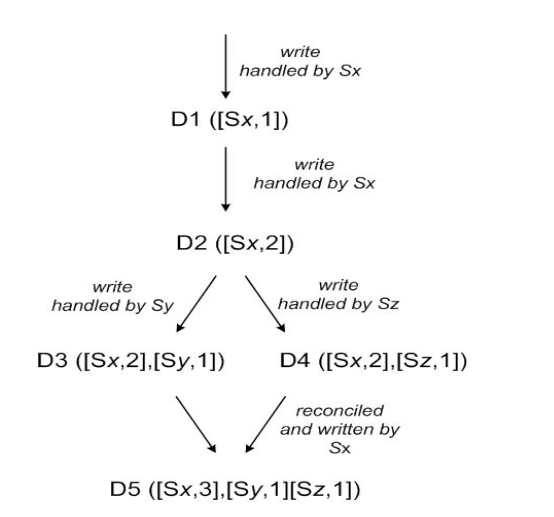
What happens if the number of object versions and the size of the vector clocks grows too large?
- Theoretically will not happen because writes are handled by one of top "N" nodes in the preference list.
- Vector clock sizes are limited to a fixed size and older entries are removed.
Consistency Protocol
R is the minimum number of nodes that must participate in a successful read operation. W is the minimum number of nodes that must participate in a successful write operation. Setting R and W such that R + W > N yields a quorum-like system.
Tuning these parameters allow Dynamo to be a high performance read engine if required. eg: R=1, W=N
Put Request
- Coordinator generates the vector clock for the new version and writes the new version locally. The coordinator then sends the new version (along with the new vector clock) to the N highest-ranked reachable nodes. (Usually Top N nodes from the key's preference list) If at least W-1 nodes respond, then the write is considered successful.
Get Request
- Coordinator requests all existing versions of data for that key from the N highest-ranked reachable nodes in the preference list for that key, and then waits for R responses before returning the result to the client.
The catch is that Dynamo does not operate a true quorum, but a "sloppy quorom". i.e all read and write operations are performed on the first N healthy nodes from the preference list, which may not always be the first N nodes encountered while walking the consistent hashing ring.
Temporary Failure Handling
- If a node 'A' that is supposed to be responsible for a write of the key is down. Another node 'B' that is within the Nth successor range receives the write and stores it as a "hinted replica". Once 'A' is back up, 'B' delivers the hint to 'A' and deletes it from its local store.
Permanent Failure Handling
What if the node holding all the "hinted replica" dies?
- Dynamo uses an anti-entropy (replica synchronization) protocol to keep the replicas synchronized.
How?
- Merkle hash trees - They are an efficient data structure for comparing large amounts of data.
- Each node maintains a separate Merkle tree for each key range (the set of keys covered by a virtual node) it hosts. This allows nodes to compare whether the keys within a key range are up-to-date. In this scheme, two nodes exchange the root of the Merkle tree corresponding to the key ranges that they host in common. If the root hashes are different, the hashes of the children are exchanged, till its determined at what level the hashes are different and from there gather the list of keys that are "out of sync".
Membership
- Command line based tool triggers addition/removal of a node from the ring. Other nodes are notified through a gossip protocol that a node joined/left the ring.
- When a node starts for the first time, it it chooses its set of tokens (virtual nodes in the consistent hash space) and maps nodes to their respective token sets.
Opinion: How does it choose the portion of the consistent hash space that it is responsible for? without that information a node could choose a portion of the consistent hash space that is receiving zero traffic. The performance on the entire Dynamo system may not change at all because of an addition of a new node. Edit: Further in the paper, authors mention that there were multiple strategies attempted.
External Discovery
- Nodes have separate mechanism to discover certain special "seed" nodes. This helps with avoiding partitions in the system, Eventually all nodes will get to know about new members in the system through the gossip protocol.
Opinion: This goes against one of the tenets mentioned in the earlier part of the post of symmetry. It's perhaps to be interpreted as symmetry of some smaller subset of operations, since there are special actors across the nodes.
Node Failure
- There is no global view of the status of a node "A". It is only determined by other nodes that wish to communicate with "A". Explicit node arrival/departures from the system are determined as sufficient.
Common Dynamo Configurations
- The common (N,R,W) configuration used by several instances of Dynamo is (3,2,2). These values are chosen to meet the necessary levels of performance, durability, consistency, and availability SLAs.
Optimizations
- Nodes maintain an object buffer in-memory. Every write operation is written to that buffer. Separate writer thread flushes the writes to disk periodically.
- Whenever a node gets a read operation, the nodes check the in-memory buffer before accessing disk. If present, the object is returned from the in-memory buffer. Otherwise, the object is retrieved from disk.
Durability is a trade-off. The hosts with the in-memory buffer can crash. To overcome this, the Co-ordinator node instructs one of the "N" nodes responsible for the key to perform a "durable" write. This does not effect performance since the writes only wait for W responses. (This works because: W < N).
Partition Strategies
- Strategy 1: T random tokens per node and partition by token value
- Strategy 2: T random tokens per node and equal sized partitions
- Strategy 3: Q/S tokens per node, equal-sized partitions
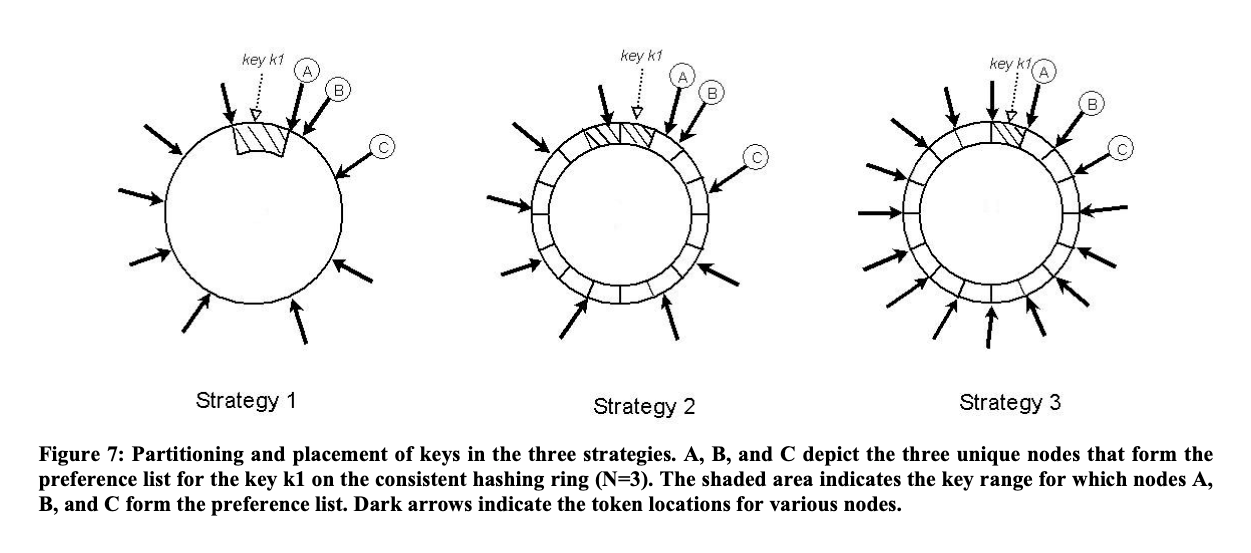
Strategy 1
- Unequal partition ranges, because the partition ranges are just defined by laying the tokens in the hash space in order. Every two continuous tokens define a range.
- Goes back to earlier point of not being able to add more nodes to handle extra request load, since the performance is non-deterministic.
Strategy 2
- Q equally sized partitions.
- Q is usually set such that Q >> N and Q >> S*T, where S is the number of nodes in the system.
- Partition scheme does not depend on the tokens.
Strategy 3
- Each node is assigned Q/S tokens where S is the number of nodes in the system. When a node leaves the system, its tokens are randomly distributed to the remaining nodes such that these properties are preserved. Similarly, when a node joins the system it "steals" tokens from nodes in the system in a way that preserves these properties.
Strategy 3 comes out to be the best.
- Size of membership information per node is the least.
- Faster bootstrapping/recovery.
- Ease of Archival.
Opinion:
The above section requires some more in-depth analysis to showcase why Strategy 3 is the best. Expect an update.
Divergent Object Versions
- Network Partitions
- Excessive concurrent writers
Client or Server driven Co-ordination
- Load-Balancer forwards a request it receives uniformly to any node in the ring. Write requests require a Co-ordinator node (top node from the preference list for the key). Read requests do not.
- Clients can poll a dynamo node to figure out which nodes are in the preference list for their key of choice. The requests can then be routed directly to that node, this avoids a network hop and a need for a load balancer.
Background vs Foreground
- Only grant and allow background tasks in time slices depending on the measurement of how much load foreground tasks are currently causing (latencies for disk operations, failed database accesses due to lock-contention and transaction timeouts, and request queue wait times). The "admission controller" manages this process.
Conclusion
- Primary advantage of Dynamo is that it provides the necessary knobs using the three parameters of (N,R,W) to tune their instance based on their needs.
- For new applications that want to use Dynamo, some analysis is required during the initial stages of the development to pick the right conflict resolution mechanisms that meet the business case appropriately
- Dynamo adopts a full membership model where each node is aware of the data hosted by its peers. To do this, each node actively gossips the full routing table with other nodes in the system.